Python-推薦系統社群網路
過了許久多少有些流量,這邊介紹利用這些流量建立推薦系統,主要利用同個 Session 下有被瀏覽過的文章都會建立文章間的關係,再利用先前說的 Louvain 社群發現將文章分類。
資料來源
資料來源主要為 GA 可以拿到的,不過在 SessionId 需要先行設置,可以參考 Simon 的網站。
1 | # Import Libraries |

資料整理
1 | # Clean Data |

建立文章間權重
當同個 Session 有瀏覽過多篇文章,則將文章間的權重設為文章數的倒數,最後將權重加總。
1 | session_group = df.groupby('SessionId')['Page'].agg(list).reset_index() |

Louvain 演算法分群
1 | # Create Graph Data |

分群結果
1 | page_label = df.drop_duplicates(['Page', 'PageTitle'])[['Page', 'PageTitle']] |

分群結果貌似還可以,分為 GA>M 、 GA&python 、 python ,不過還需要找時間進行驗證。
本部落格所有文章除特別聲明外,均採用CC BY-NC-SA 4.0 授權協議。轉載請註明來源 隨勛所欲!
相關推薦
2020-03-31
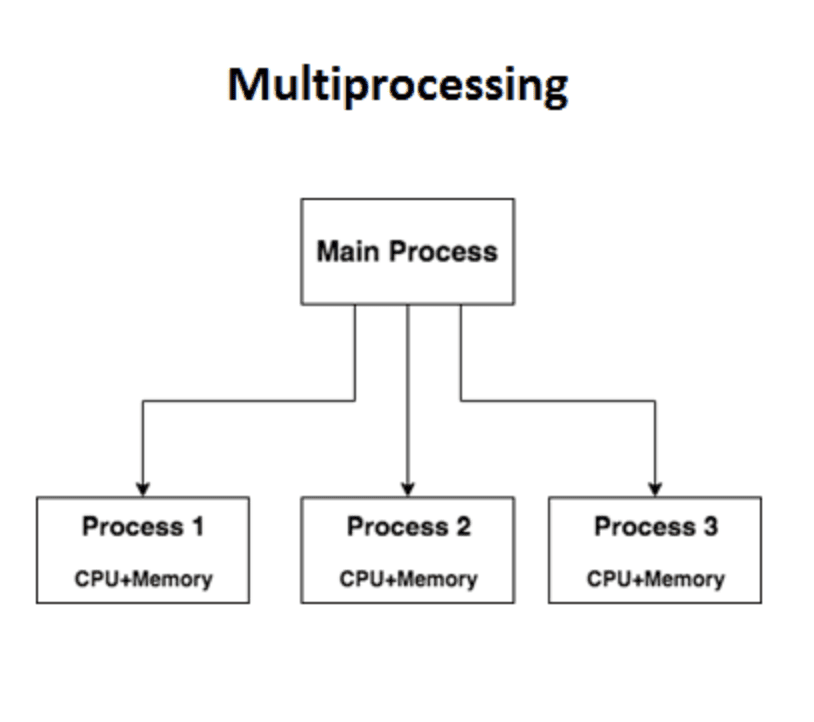
Python 多執行緒 (multiprocessing)
Python multiprocessing 筆記
2019-12-16
Python:Google Analytics Reporting API 快速入門
本文教 Analytics Reporting API v4 的 Python 快速指南,使用服務帳戶(Service application)取得報表資料,大部分都是程式碼,說明較少。
2019-12-10
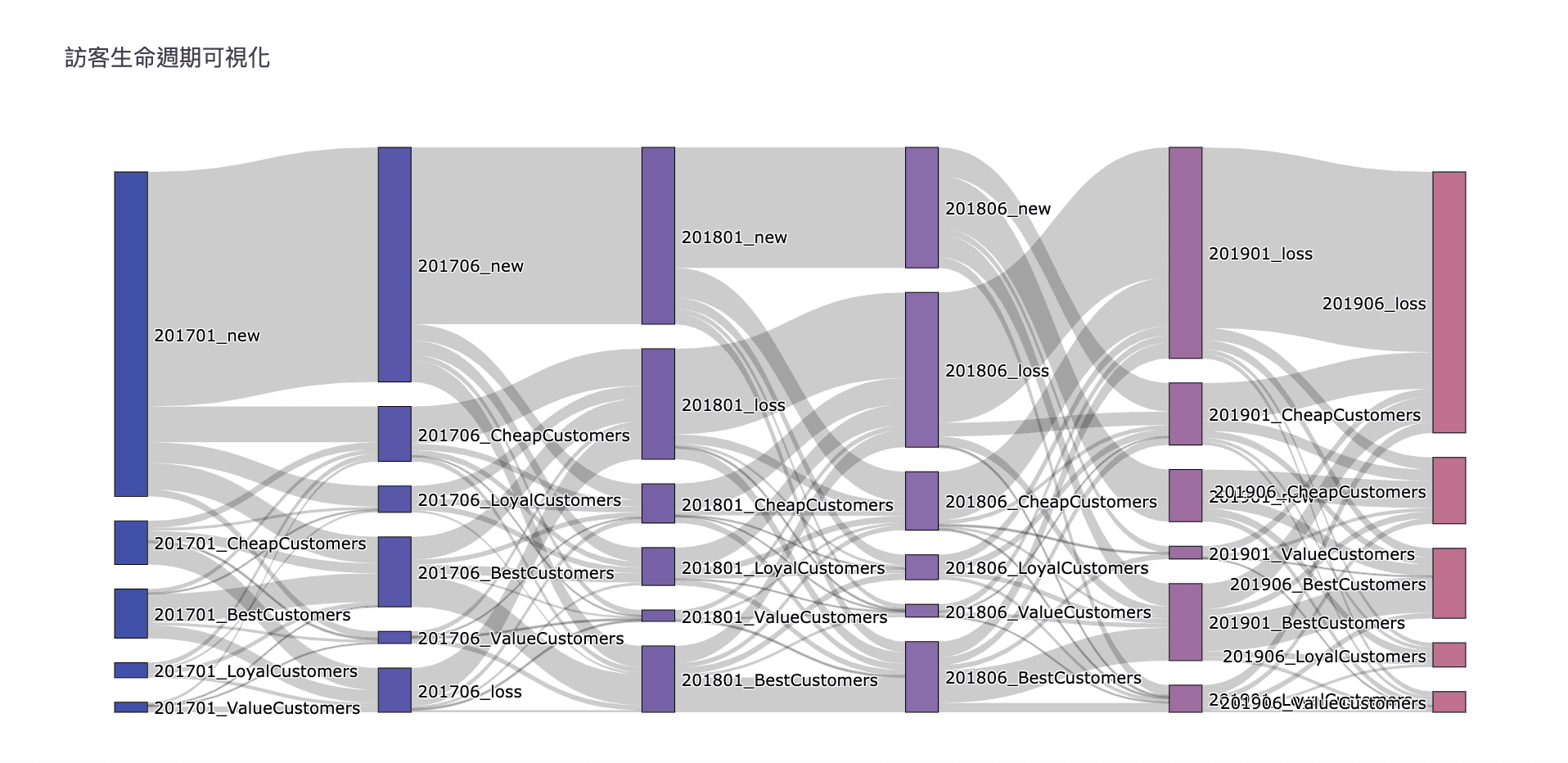
Python 實現桑基圖(Sankey)
本文介紹如何使用 Python 實現桑基圖(Sankey),將 RFM 用戶分析模型的分群結果視覺化,觀察不同時間點的用戶群體變化。包含完整的程式碼實作與視覺化分析。

2020-06-17
Python networkx 筆記
本文介紹 NetworkX 函式庫的基本使用方法,包含如何建立網路圖、添加節點和邊、設置權重,以及使用不同的佈局方式進行視覺化。適合需要進行網路分析和圖形視覺化的開發者參考。

2020-05-28
Python getopt 命令列參數
Python 提供 `getopt` 模組,提供幫助解析命令列的選項和參數。另外可以透過 `sys.argv` 取得命令列任何參數。
2019-11-29
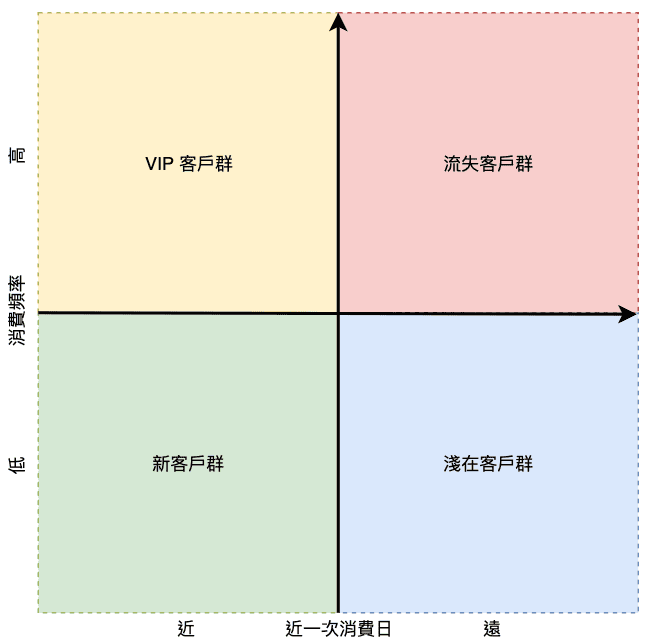
Python 實現 RFM 用戶分析模型
本文介紹如何使用 Python 實現 RFM 客戶價值分析模型,透過近期購買行為、購買頻率、購買花費三項指標來評估客戶價值。包含完整的程式碼實作與視覺化分析。
評論